

虽说肝活动是手机游戏体验的一环,但在一个效率至上的时代玩家们想要一键刷任务脚本/BOT 也是在情理之中,之前日本玩家就已经针对各种手游制作过物理外挂,比如 LLSIF 自动打歌器,FGO 无限池自动点击器等等,而现在技术宅们已经不满足物理外挂,而是利用人工智能技术、神经网络算法制作出了可以自动选择 BAQ 卡牌的 FGO AI BOT 并将其命名为「Project Pendragon」,并且还通过加强学习技术打造出了升级版的 Pendragon Alter Bot。
Michael Sugimura 创造的「Project Pendragon」人工智能 BOT 是利用三个神经网络在 FGO 中由 BOT 自己决定在什么时候出什么样的卡(ABQ),据「Project Pendragon」的制作者自己的体验,使用这个 BOT 后为他在 FGO 游戏中节省了很多时间,尤其是在早上他会让 BOT 替自己刷 10 分钟到 15 分钟的 FGO。

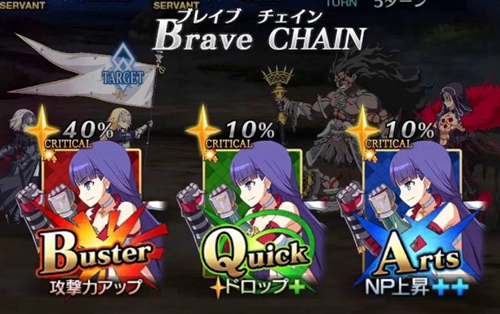
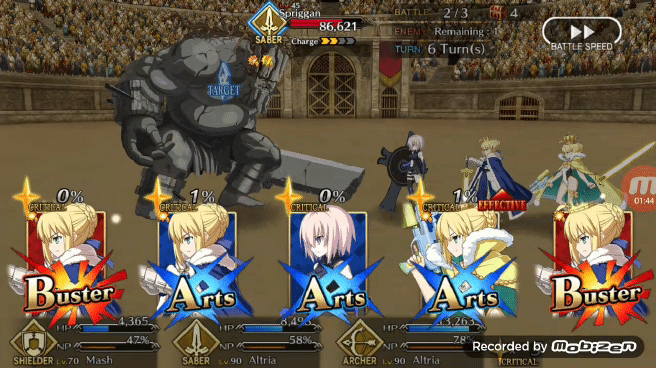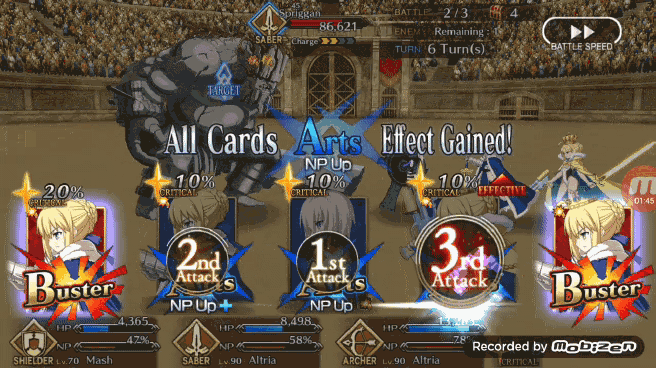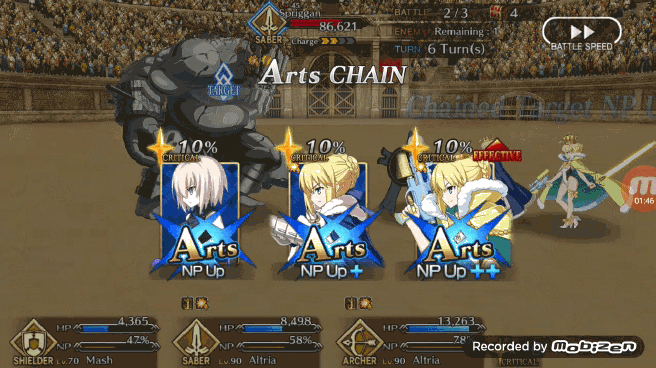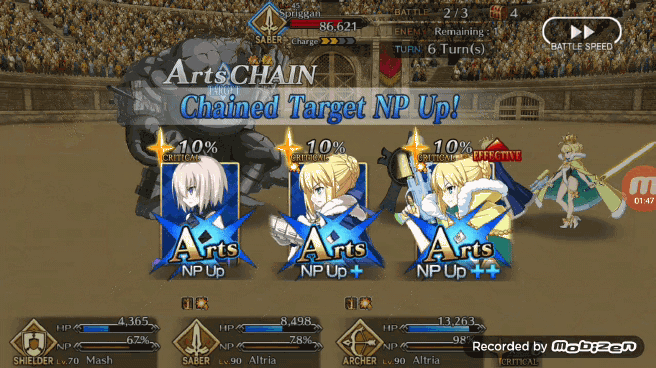
FGO 的游戏规则是在一个回合中玩家需要从游戏给出的五张手牌中选择其中三张对敌人进行攻击,手牌有三种类型 B 卡(加攻击)、A 卡(加 NP)、Q 卡(加暴击星),每种类型的手牌总共有多少张取决于队伍中的角色,五张手牌是来源于队伍中三位角色自带的 15 张手牌(3 角色×每人五张自带手牌)。另一个重要的游戏机制是卡牌的 BUFF 奖励/攻击奖励,三种类型相同的卡牌有 BUFF 奖励,三张同一角色的卡牌可以带来额外攻击。
作者的思路是建立一系列的神经网络让机器来玩 FGO,再通过 python 将机器的选择输入到游戏中实现自动选择卡牌刷本,对于 BOT 来说一个基本但有效的游戏策略就是尽量的让自己选择的卡牌能够形成奖励,为角色加 BUFF 或者伤害效果,使得战斗更有效率从而缩短游戏时间。
BOT 的逻辑结构
1、在 BOT 启动时,BOT 自己会检测是否看到攻击按钮,如果发现了攻击按钮就会进入到出牌策略选择阶段,从五张手牌中选择要打出的三张牌
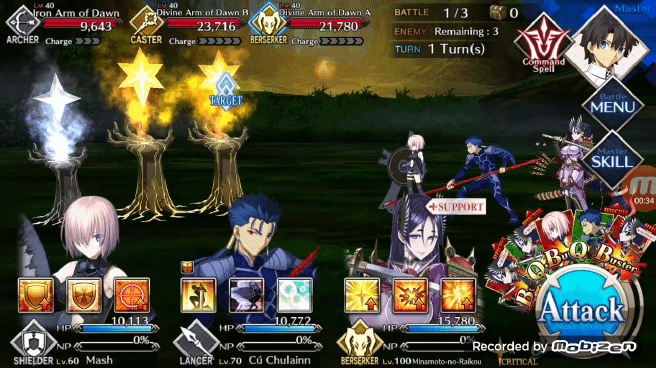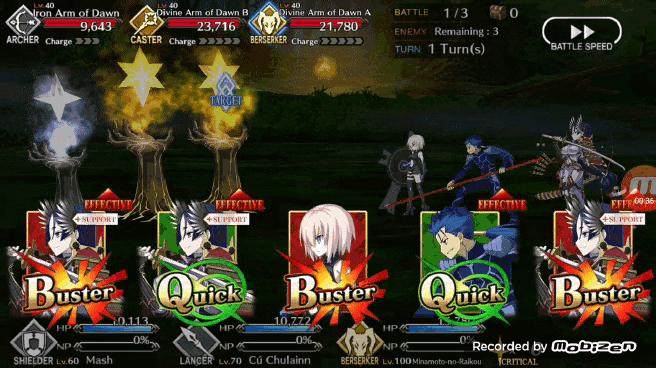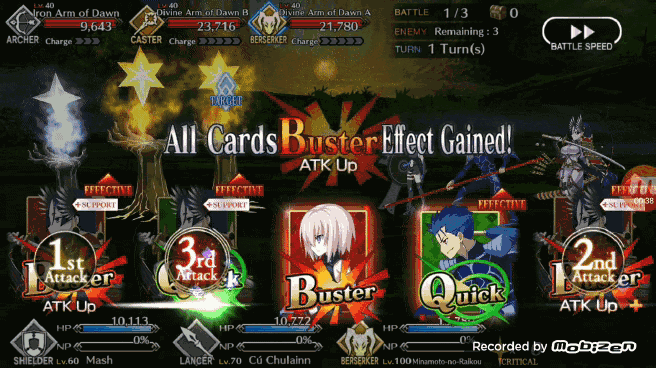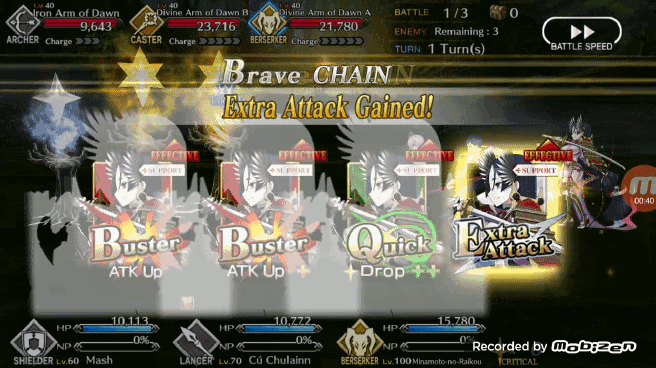
2、BOT 首先还是检查 5 张牌当中是否有三张相同角色的手牌,如果有 BOT 会优先选择「brave chain」(第一张牌选择红卡)。
3、如果 BOT 发现无法打出「brave chain」,BOT 会检测五张手牌的类型(ABQ),优先选择三张相同类型的牌,打出 BUFF 奖励(加攻击/加 NP/加星)。
4、如果 BOT 还是找不到可以到处的「chain」,则会按照 A、B、Q 的优先顺位出牌(作者本人的出牌风格优先考虑打 A 卡集 NP)。
以上步骤一旦完成,BOT 将再次开始检测是否出现攻击按钮,出现的话就会进入到下一次的判断。
在这个 BOT 出牌的逻辑判断过程中,识别攻击按钮与卡牌类型并进行处理是一个经典的卷积神经网络(CNN)而识别处理同一个角色的三张手牌则是孪生卷积网络(siamese CNN)
作者使用 PyTorch 构建了两个卷积神经网络并用 NVIDA 1080、1060 GPU 作为硬件设备训练网络。
但在此之前让 FGO 在 PC 上运行的难度超出了作者的想象
Bot 自己选择的源赖光三连
理论上在 PC 上玩 FGO 应该是件很简单的事情,但 Google 一下就知道现在市面上没有一款模拟器可以轻松支持 FGO,而且 FGO 还不支持安卓设备打开开发者模式(打开后无法进入 FGO 游戏)。在经历了短暂的绝望后作者想到了使用 TeamViewe 来控制自己的安卓设备的方案,尝试一下后发现效果很好,唯一的缺点就是长时间使用手机发热惊人。
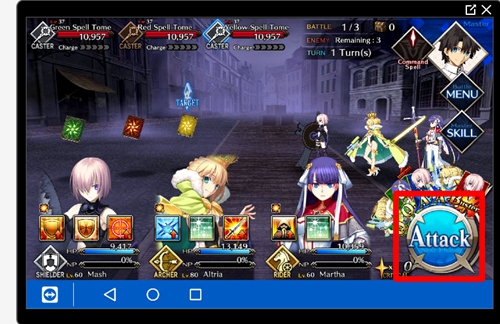
在用 TeamViewer 设置后 PC 与手机端后,作者成功启动 FGO 并且通过 python 的 PyAutoGUI 成功的向手机发送了鼠标点击指令,之后就是真正的通过 FGO 中的游戏行为让神经网络进行学习。
在 FGO 游戏中只有玩家按下攻击按钮才会看到给出的五张手牌并从中进行选择,我们让 BOT 每秒钟检测一次攻击按钮,如果检测到再执行后续的代码。
点击攻击按钮之后就是要确定手牌在屏幕上的位置,FGO 中的五张手牌总是位于屏幕上相同的位置也就是手牌出现的位置是固定的,这就让我们可以标识出手牌并输入到神经网络当中。
在学习的过程中根据实际情况作者也对神经网络进行了一定的调整
使用 TeamViewer 将 PC 端与安卓端相连
要让 Bot 识别出不同的卡牌类型
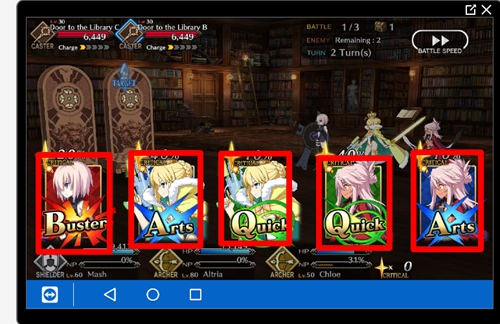
作者截取了几十个出现攻击按钮和没有出现攻击按钮的游戏画面,还截取了大约 60 张不同颜色手牌的 FGO 游戏图像,尽管案例图像上的角色并不相同,但是卡牌颜色之间是有共同性的,他希望 BOT 优先考虑卡牌的颜色(颜色代表卡牌类型)做出判断。在积累了两个案例数据集后,作者借助 Pytorch 的预训练网络进行学习,并对预训练网络进行了一些微调。
作者最终选择使用 ResNet 50 模型进行神经网络的训练(作者想看看在自己显卡上使用较大的 Resnet 50 模型要花多长时间 ),对于每个神经网络进行了 5 个周期的训练,学习后的两个分类任务(识别 Attack 与识别卡牌类型)精确度都达到了 95% 以上。
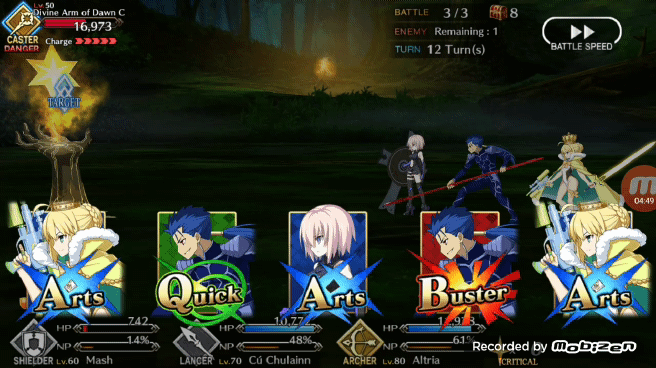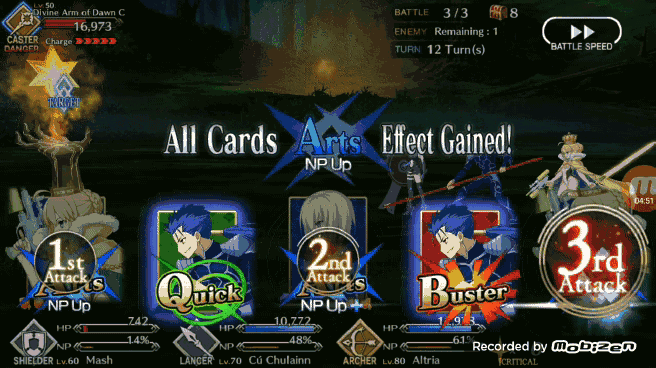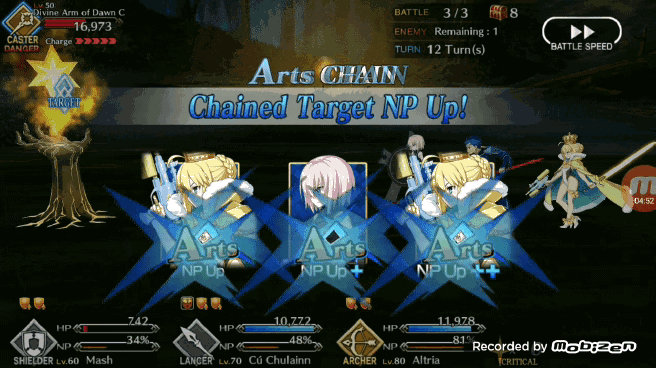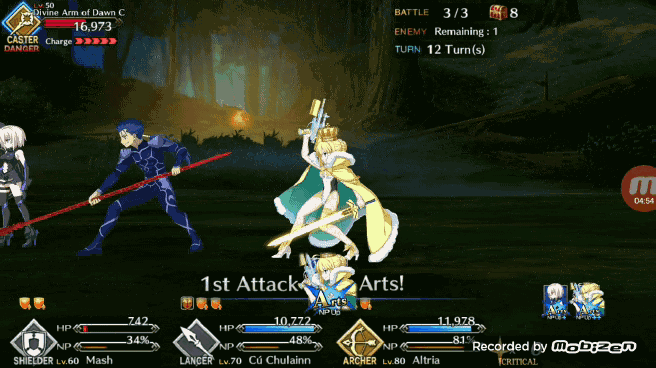
用于确定卡牌类型的神经网络使用的是 ResNet 50 模型这也构成了 BOT 的主干,因为在 FGO 中只要 BOT 确定好卡牌的类型就可以尽可能的实现「chain」。
Bot 实现的蓝卡 Chian
使用孪生卷积网络寻找「brave chain」
如同上面所说 FGO 的另一种出牌奖励是相同角色的三张卡牌可以构成「brave chain」增加一次额外攻击,要想让 BOT 能够自动识别相同角色的卡牌并且使出「brave chain」,有好几种方法可以实现这个需求,第一个就是建立一个经典的卷积神经网络,让这个卷积神经网络能够识别出 FGO 游戏中现存的所有角色,但是考虑到 FGO 角色众多以及处理数据,这个方法很麻烦。所以作者决定使用孪生卷积网络(siamese CNN)实现这个需求。
孪生卷积网络的优点在于可以使用相当小的数据集来训练出一个神经网络,以便在不同颜色的卡牌中能够更好的进行角色相似度识别,而且也方便我们相当大程度的增加数据集。作者对于孪生卷积网络也进行了一定的调整,修改了网络结构让网络包含了 Maxpooling。孪生卷积网络被训练成最大化或者最小化两个输入图像的特征向量之间的欧几里得距离,这取决于图像之间是否相同。这个模型可以测试对比一张手牌与其他四张手牌,并判断是否相似,但这个模型的缺点就是要将每张卡牌与其余四张卡牌进行对比,所以在最差的情况下运算时间是 N²。
我们可以输入图像通过两个输出向量之间欧几里得距离,可以得到 siamese CNN 所看到的两张图片的不同之处,数值越低意味着图片越相似,FGO 中的很多角色侧脸非常相似,所以需要更多的图像数据进行对比来强化网络的判断。
马修与自己以及其他角色的对比数值



马修与梅林的差异度数值意外的小

孪生卷积网络自动选择的泳装 Saber 「brave chain」
距离一个完美的 FGO 自动游戏 Bot 还有多远的路?
这个 FGO Bot 在玩 FGO 上的表现还是非常称职的,但是 Bot 并没有理由游戏中的其他机制来进一步的提升效率(Bot 本身的判断逻辑是单纯的以手牌系统为基础)。
在 FGO 中角色发动宝具需要集满 NP,作者设定让 Bot 在经过一定的回合数后再发动宝具,以避免将宝具提前浪费在杂兵身上。
FGO 当中还有职阶相克系统。职阶相克可以给予敌方更高的伤害。
FGO 当中还有角色技能,这些技能会带来不同的效果,在正确的时机使用可以带来攻击提升、回血等效果,角色技能系统在 FGO 战斗中非常有用,但目前 Bot 并不能自动使用技能。
这个 Bot 的下一步是做成强化学习应用,但 FGO 游戏存在 AP 系统,每一次战斗都需要消耗一定的 AP 点数,如果耗光就需要自然恢复或者吃金苹果、银苹果快速恢复,所以这就让我们很难在 FGO 游戏里进行数千次的行为迭代,替代方案是构建出一个模拟的 FGO 游戏环境供 BOT 进行探索,但这非常耗时。
「Pendragon Alter」的诞生
「Project Pendragon」的核心是两个卷积神经网络与一个孪生卷积网络组成的 BOT,利用强化学习技术我们的目标是让 Bot 能够自己选择卡牌而不用再为 Bot 人为制定规则,这就需要构建出一个 FGO 游戏环境,让 Bot 从头开始在 FGO 游戏中进行探索,那么我们该如何简单构建一个 FGO 游戏环境让 Bot 在其中游戏学习构建神经网络呢?
作者将经过训练并整合的全新加强学习网络装回到游玩 FGO 的框架环境中,作者将这个新的网络称为「Pendragon Alter」。FGO 中就有一些角色的 Alter 版本,运营可以以此在不用增加大量额外开发的情况下,制作更多的游戏角色(并且增加氪金收入)。
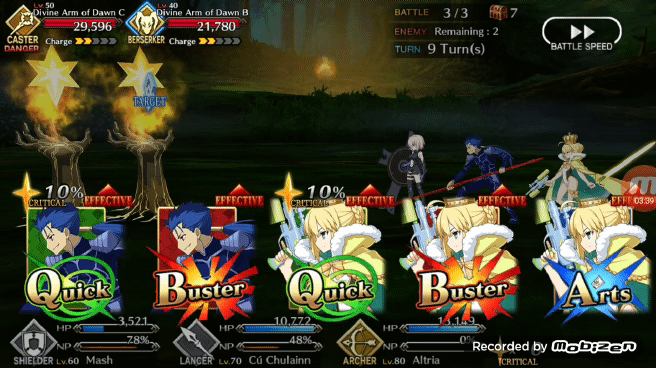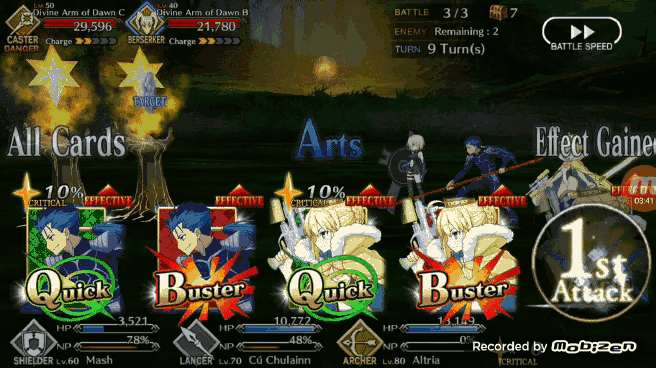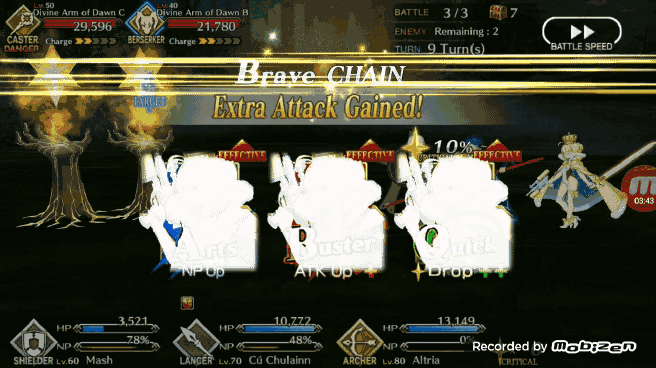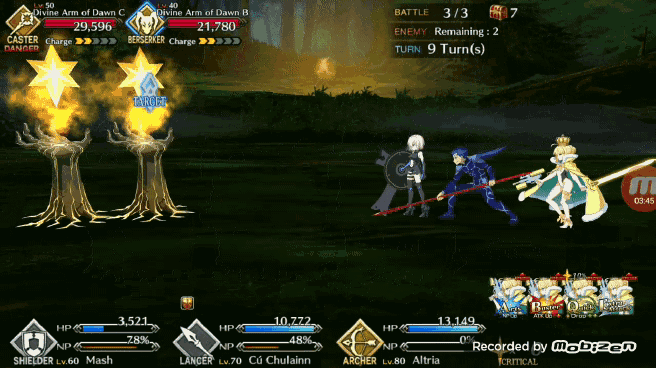
Pendragon Alter 使出的「Arts chain」(三蓝卡)
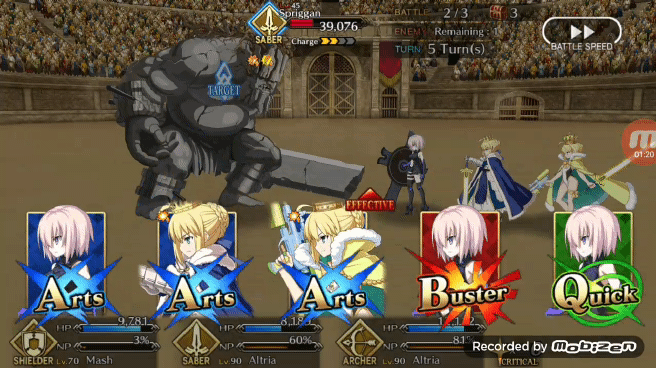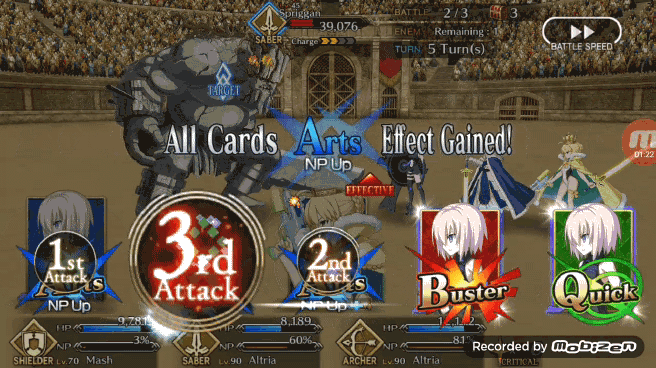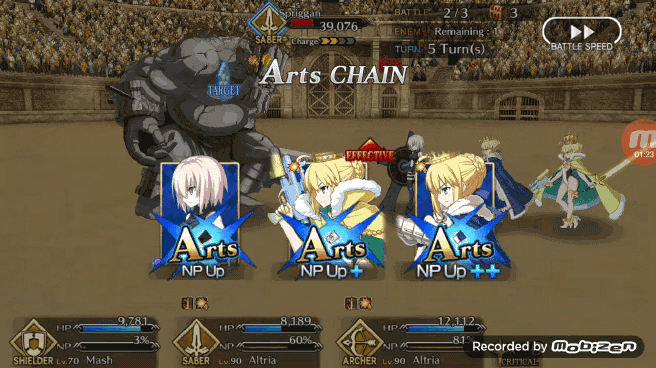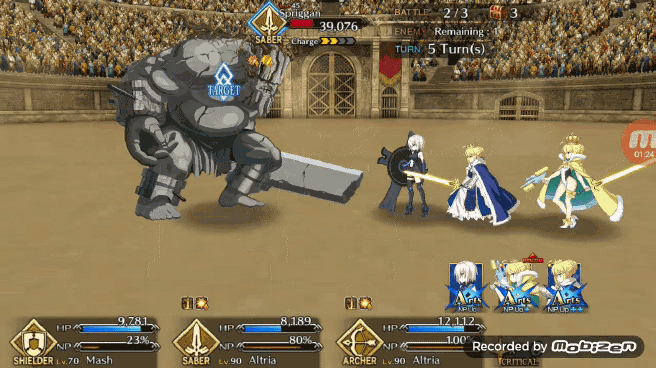
作者构建 FGO 游戏环境使用的是 OpenAI gym 库,在 FGO 中玩家通常在任何给定时间里都有三个角色在战斗要打退 3 波 9 个敌人(大多数时间如此),为了简化这个战斗环境,作者将游戏环境设计成一对一战斗,战斗双方的目的是通过回合制伤害将对手的 HP 减到 0.
这些一对一战斗的结构基本上是一个循环,每次迭代都取决于一个队伍将另一个队伍的 HP 砍到 0。敌方每回合选择一个范围内的随机数作为伤害值,玩家角色则是根据每回合打出的三张手牌进行伤害输出,每回合出现的五张手牌是根据 FGO 角色初始牌组出现的。在攻击伤害循环构建完成后,作者根据目前已知的 FGO 游戏内的伤害加成机制和数值,在后台添加了相关的参数,包括 NP、暴击星、Chain 奖励(比最初更复杂,还考虑到了第一张卡的类型带来的三种不同 Chain 效果)
而在构建模型的动作空间(Action Space)这一步作者遇到了难题,在第一轮头脑风暴中作者希望模型可以根据所有可能的方法对不同的手牌进行分类,从 ABQ 三种卡牌类型中构建出一个手牌输出,但很快就遇到了如下问题
手牌 A、Q、Q、B、A
输出 Q、Q、Q、
手牌只有两张蓝卡但输出却是 3 张蓝卡,这就产生了冲突,为了解决这个问题作者想到的解决方法是让模型的动作空间(Action Space)变为从 5 个卡牌中选择 3 个卡牌的所有可能排列 A(5,3)=60,不考虑卡牌类型在两次手牌之间的变化,而是要保证输出的结果是来自五个有效的卡牌, A(5,3)的 60 种排列很好的表示了动作空间。
Hand: “Arts”, “Quick”, ”Quick”, “Buster”, “Arts”
output_1: “Card 1”, “Card 2”, “Card 3”
output_2: “Card 1”, “Card 2”, “Card 4”
…
output_60: “Card 5”, “Card 4”, “Card 3”
从第 1 种到第 60 种输出都是有效的,在这样的动作空间中我们建立的任何网络都是用 5 个输入节点代表 5 张手牌,60 个输出节点代表 5 选 3 的所有可能排列。
作者最开始担心的是神经网络能否自己概括出「打出三张相同类型的卡牌是个好的选择」的概念,给定输入向量
Hand_1: “Arts”, “Arts”, ”Quick”, “Buster”, “Arts”
Hand_2: “Buster”, “Quick”, ”Arts”, “Arts”, “Arts”
作者担心神经网络是否可以概括出打出手牌中的三张蓝卡都是个很好的策略,“Card 1”, “Card 2”, “Card 5″ 与“Card 3”, “Card 4”, “Card 5” 都有相同的效果,不过神经网络最后确实自己就学会了
Pendragon Alter 自己选择以“Card 3”,“Card 2”,“Card 4” 顺序打出的三蓝
Deep Q-Learning
在强化学习的环境中,没有原始数据集我们允许一个神经网络探索一个环境的动作空间,在这个环境中由于不同的选择它会受到奖励或者惩罚,这样神经网络就可以尝试如何以最佳的方式适应于这个环境。在 FGO 游戏环境中也就是要让网络判断出 60 种出卡选择中哪一种是最好的,在强化学习中有探索与开发概念(exploration vs exploitation)。有的时候一个行为应该是出于随机选择而不是简单由神经网络(本案例)来做最优选择,这有助于我们的神经网络继续探索并寻找到额外的奖励,否则神经网络就只是利用了它已知的奖励,不会找到额外的奖励。
我们可以通过向神经网络输出的卡牌组合添加奖励来实现让 Bot 能够强化更好的选择同时考虑到错误的选择,让神经网络在不断的奖励与自我迭代当中探索对于游戏最优可能性选择。
而对于 Bot 的奖励最初以战斗结果来定,胜利数值+1,失败数值-1,这样的奖励机制让 Bot 可以展示出一些不错的手牌搭配,但是没有更进一步优化的决策比如打出 Chain,在最初的几轮训练中 Bot 的胜率很少能超过 30%,最好的成绩是 50% 的胜率,但仍然可以继续改进,为此作者又为 Bot 添加了额外奖励,让 Bot 能够使用 FGO 游戏更为复杂的机制。
作者给 Bot 添加了使用三张类型相同手牌会得到额外奖励(A 连、B 连、Q 连都行),在进行一番测试后,再度添加当 NP 积累到 100% 的时候 Bot 获得另外的额外奖励,这都是为了让 Bot 能够像真实玩家一样通过同类型卡三连放大效果,通过 NP 一次性解决敌人结束战斗,让 Bot 意识到这类操作的重要性。
这样做的一个确定可能是让 Bot 过于强调这类操作,但未来可以通过为 Bot 添加记忆机制跟踪整个战斗中的所有选择与获得的奖励,进行自我评估,而不是现在在每个回合结束后进行评估。
不过通过现在的额外奖励机制 Bot 可以在战斗当中维持 60%-70% 的胜率,并且通过后期调整在经过 5 万次战斗模拟后将胜率提高到 80%,而胜率还将有可能进一步提高。
Pendragon Alter 与 Pendragon 对比
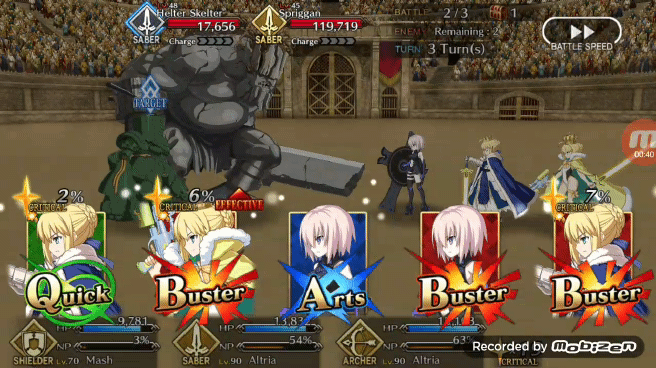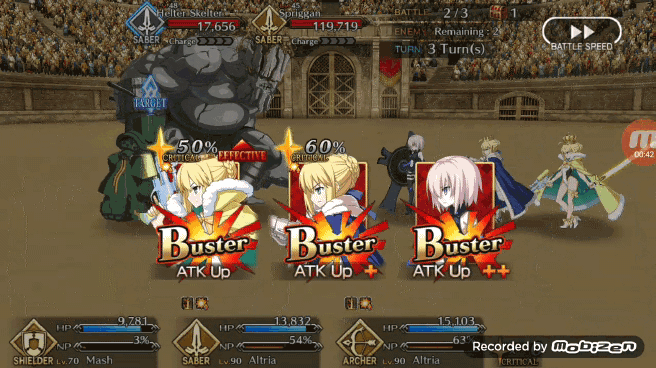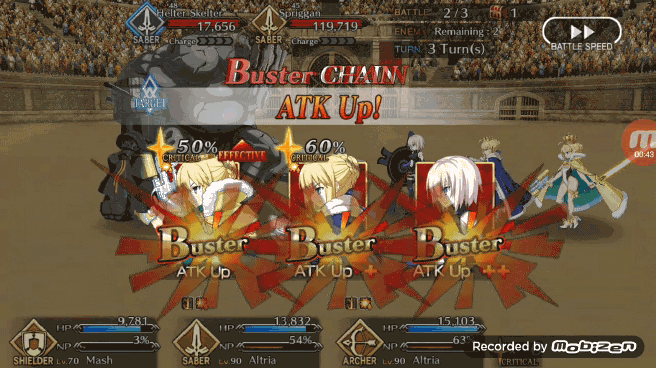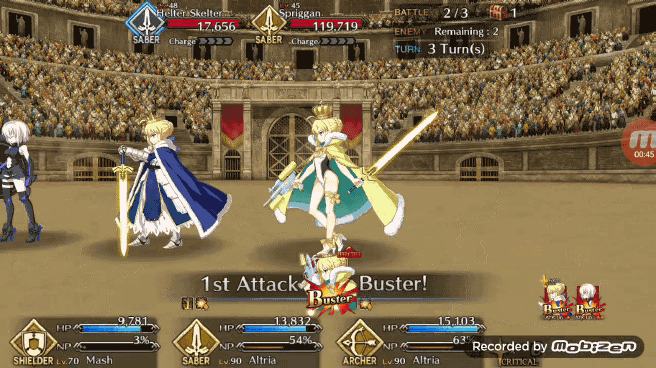
在模拟战斗中能够获得 80% 的胜率,Pendragon Alter 的表现已经不错了,现在我们可以看看 Pendragon Alter 在实际游戏中的表现。和之前一样让强化学习版 Bot 利用 TeamViewer 从 PC 端控制安卓端游戏。作者认为 FGO 游戏内的一个不错的出牌策略是让 Bot 能够在任何可能的时刻都打出 Chain,在实际游戏测试中 Pendragon Alter 能够以相当一致的节奏打出蓝卡和红卡 Chain。
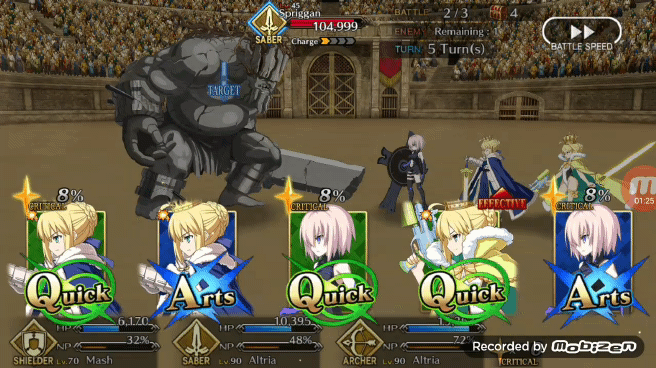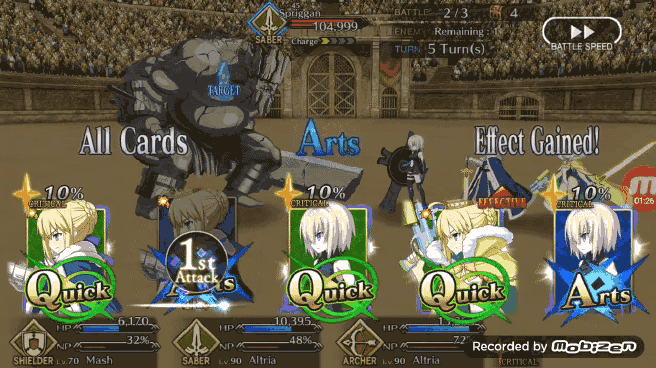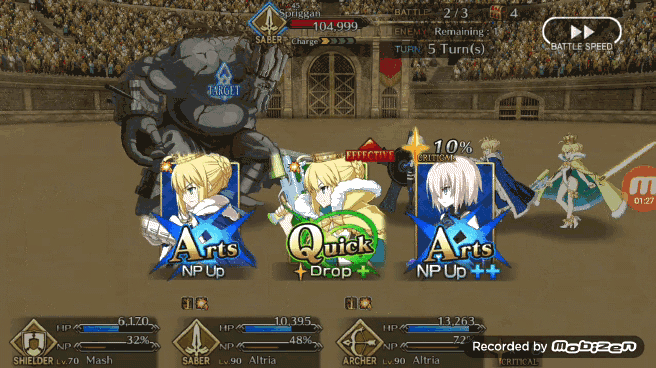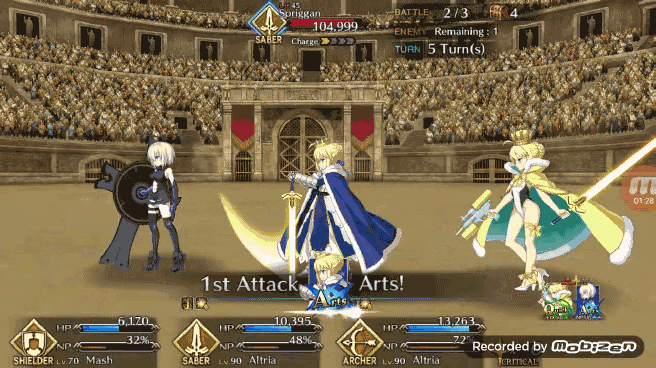
但是在打绿卡 Chian 方面 Pendragon Alter 虽然可以打出但并不像打蓝卡 Chian 和红卡 Chain 那样连贯。如果手牌有两张红卡或蓝卡与三张绿卡,如下图所示 Pendragon Alter 在 QAQQA 的手牌组合当中做出了 AQA 的选择,这样的选择是最大化了蓝卡效果。
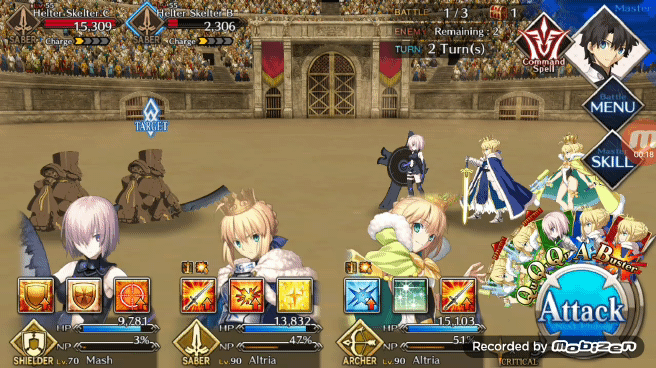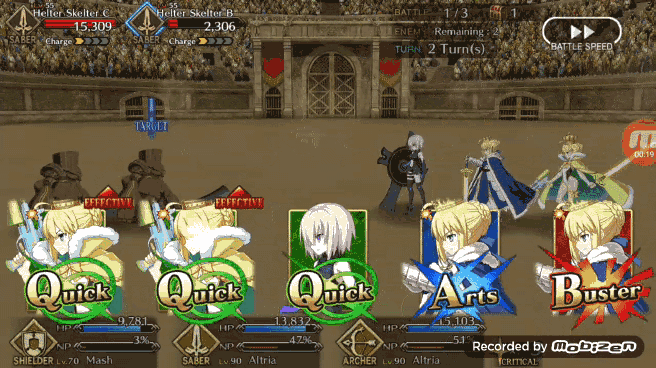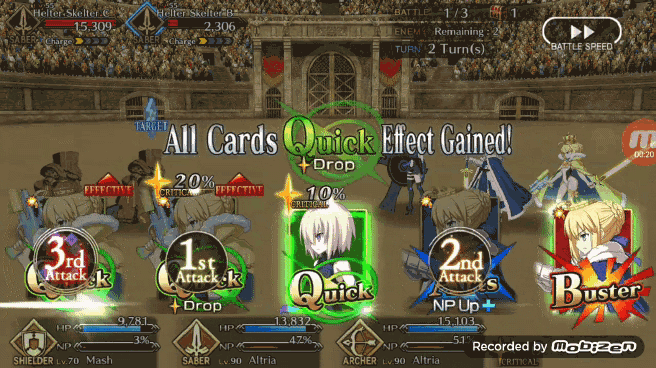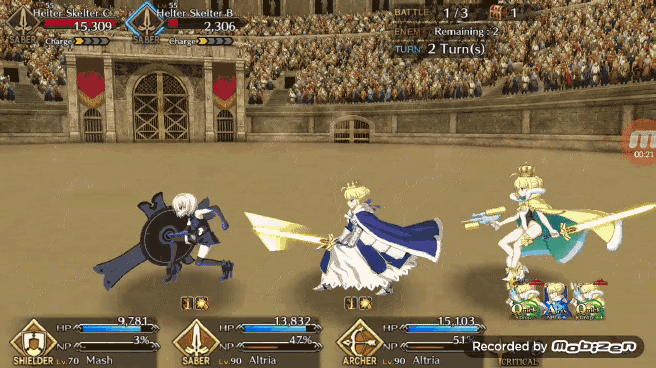
如果有三张绿卡一张蓝卡和一张红卡, Pendragon Alter 更喜欢将蓝卡或者红卡放在打出的第二张牌中,而不是做成绿卡三连。这就意味着 Bot 自己放弃了获得增加暴击星的机会,而是更乐于造成更多的伤害值或者是 NP 值。
这个现象非常有意思,这可能是在 Bot 训练的初始阶段 15 张手牌里只包含了 3 张绿卡,而蓝卡和红卡则是各有 6 张,所以 Bot 更适合打蓝卡和红卡,第二个有趣的现象是 Pendragon Alter 似乎对出牌的第一张牌和第三张牌带来的额外奖励更有直觉。
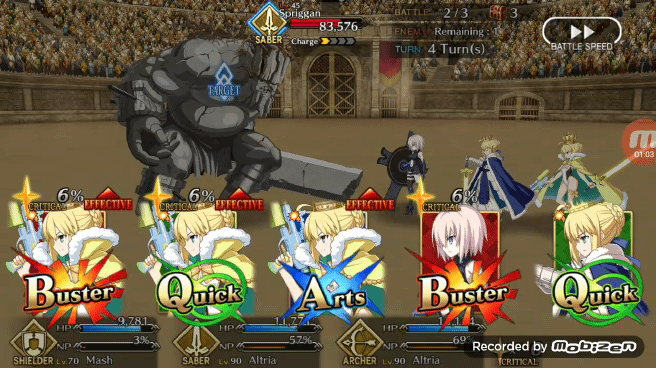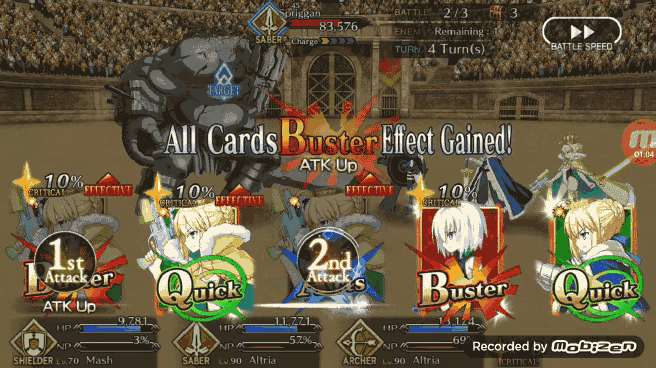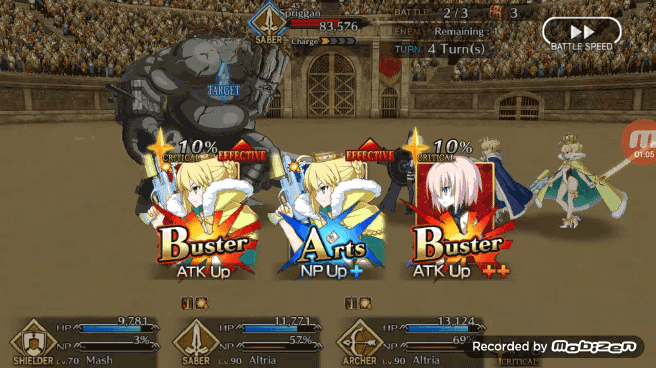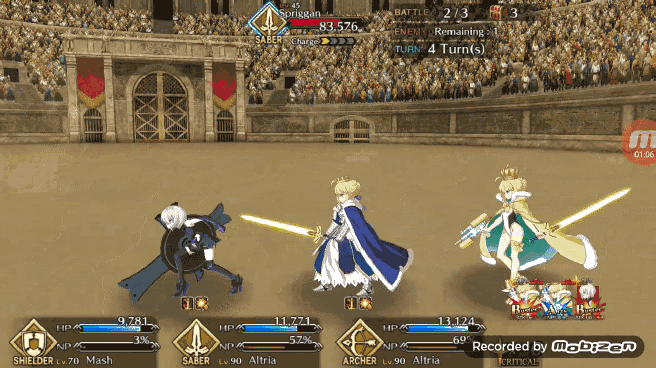
Pendragon Alter 在无 Chain 可打的情况下也会表示出对第一张牌和第三张牌奖励效果的理解,在下图的情况中Pendragon Alter 不会选择任何一张绿卡,而是打出 BBA,通过将红卡放在第一和第三的位置造成更高的伤害值,而中间的蓝卡则是可以增加角色 NP,所以基本上 Pendragon Alter 成为了一个尝试在为角色充 NP 的时候最大化输出伤害的 Bot。
当无 Chian 可打时 Pendragon Alter 的表现是优于最初的 Pendragon,因为 Alter 可以更好安排卡牌位置,还是上面的动图,我们看一下两个 Bot 是如何给出同样手牌下的出牌选择。
Hand: “Buster”,”Quick”,”Arts”,”Buster”,”Quick” BQABQ
Project Pendragon Bot: “Arts”, “Buster”, “Buster” ABB
Alter Pendragon Bot: “Buster”, “Arts”, “Buster” BAB
虽然两个 Bot 给出的出牌牌组非常相似但 AB 与 BA 两个位置的不同在 FGO 游戏中产生的效果会有很大的不同。
Pendragon 是一个主打蓝卡其次红卡最后绿卡的 Bot,这意味着 Pendragon 在可能的情况下总是在打蓝卡,但这并不会最大化蓝卡的效果或者红卡的输出。能够同时最大化红卡输出和蓝卡加 NP 效果的是 Pendragon Alter,第一张红卡和第三张红卡提升了整套伤害,中间的蓝卡则是增加了更多的 NP。
本文链接: http://www.acgdoge.net/archives/31107, 转载请注明出处



